
.png)
K-Cube Consensus Clustering with Centroid Improvement and Variance-Based Metrics on High-Dimensional Data
Abstract
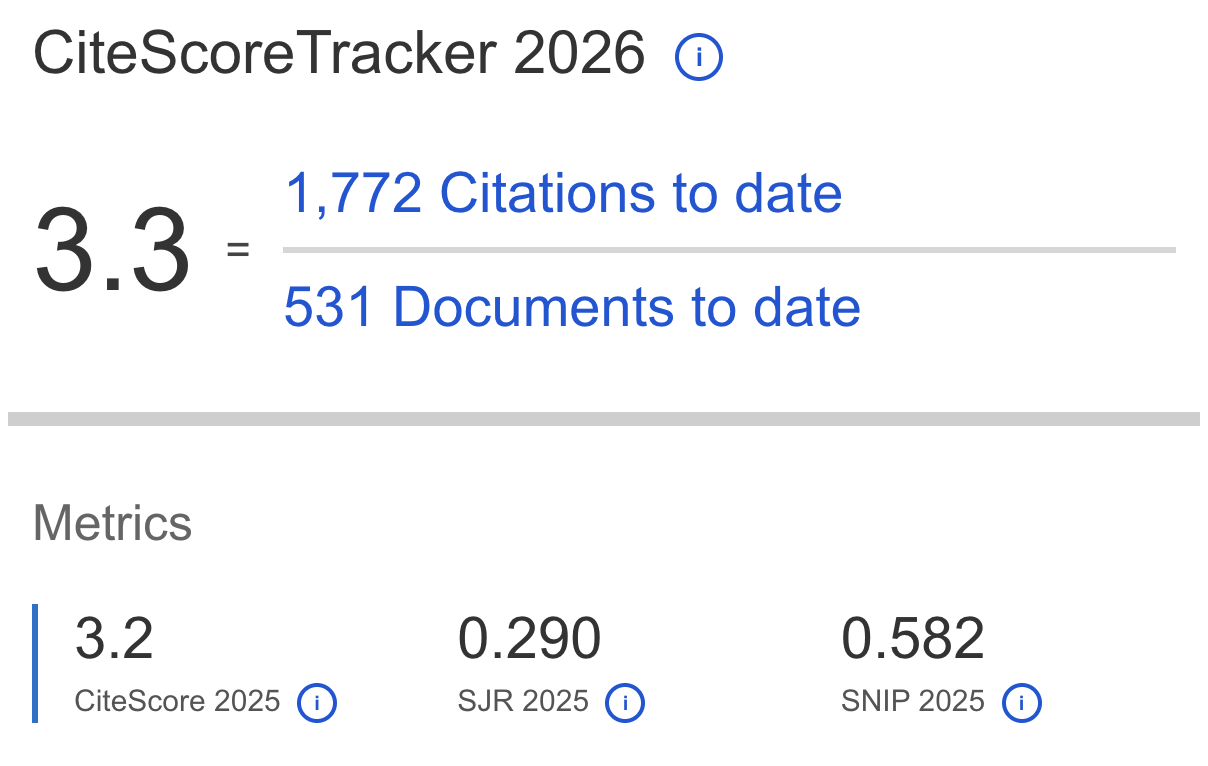
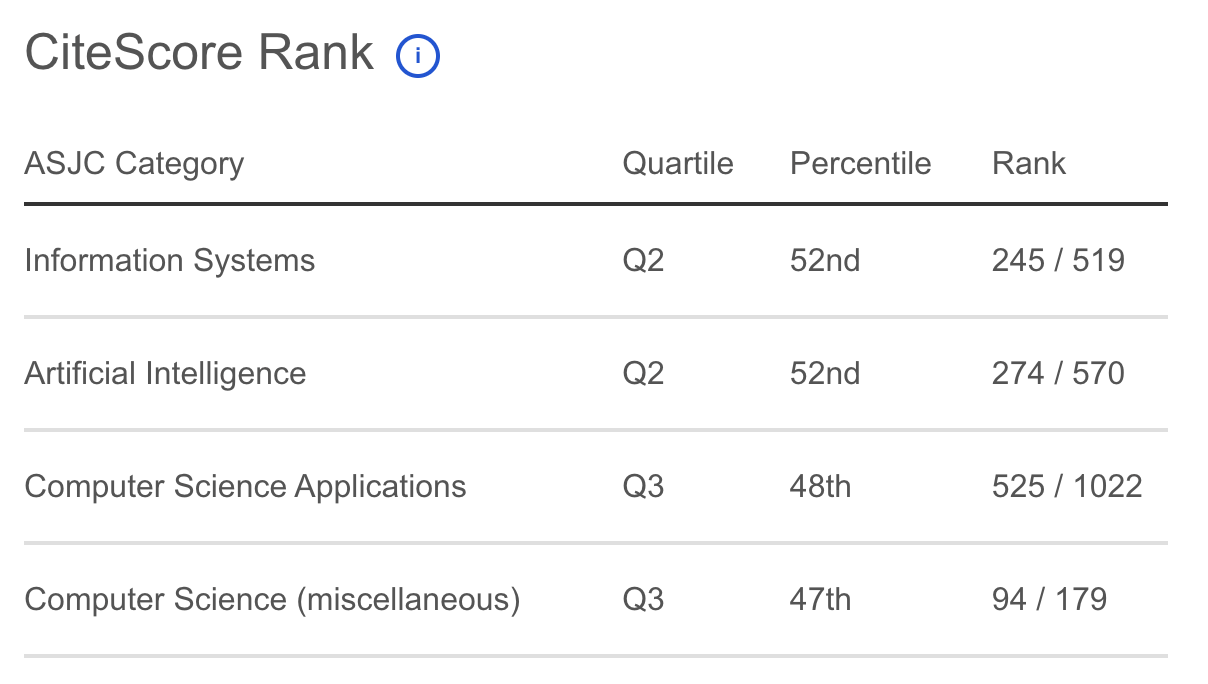
High-dimensional and multidimensional cube data structures (K-Cube) are posing a significant challenge for conventional clustering algorithms due to the effect of dimensionality, uniform feature weight assumptions, and loss of hierarchical information. Therefore, this study aimed to propose K-Cube Consensus Clustering framework, which integrates Variance-Based Centroid Refinement, Weighted Distance Metrics, and consensus voting mechanism to overcome the challenges of high-dimensional cube data. The proposed method systematically clustered all dimensions and sub-dimensions of cube data, refined centroid by emphasizing more stable low-variance attributes, and applied adaptive distance weighting based on variance-derived feature weights integrated into the distance metric to improve cluster assignment. The final clusters were obtained through majority voting of the clustering results for each dimension. Unlike existing consensus clustering methods that operate on flat data representations or combine independent clustering results, the proposed framework explicitly exploits the hierarchical structure of multidimensional cube data by clustering dimensions and sub-dimensions prior to consensus integration. Moreover, variance-based centroid refinement and weighted distance metrics are jointly embedded within each cube dimension rather than applied as isolated enhancements. This hierarchy-aware design preserves cube semantics while simultaneously improving centroid stability and distance adaptivity, resulting in a distinct and scalable clustering framework for complex high-dimensional cube data. The framework processes cube dimensions independently with iterative convergence control, enabling scalable application to large-scale cube data. The results of synthetic and real-world high-dimensional datasets, including cube data with approximately 2.2 million instances, showed that the proposed method consistently outperformed K-Means, K-Medoids, and Hamiltonian formulations. The method produced lower SSE such as 3,179,328 on Arcene and 1,422.21 on Lung Cancer, higher Silhouette Score of approximately 0.5718 and 0.4905 for consensus results, better cluster stability of 0.9947, and faster convergence. These results confirmed the effectiveness of K-Cube Consensus Clustering in producing stable and meaningful clusters in large-scale high-dimensional data applications.
Article Metrics
Abstract: 175 Viewers PDF: 82 ViewersKeywords
Full Text:
PDFRefbacks
- There are currently no refbacks.

Journal of Applied Data Sciences
| ISSN | : | 2723-6471 (Online) |
| Publisher | : | Bright Publisher |
| Website | : | http://bright-journal.org/JADS |
| : | taqwa@amikompurwokerto.ac.id (principal contact) | |
| support@bright-journal.org (technical issues) |
 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0