
.png)
Automatic Analysis of Political Discourse: A Comparative Study of Multilingual and Large Language Models
Abstract
This paper proposes the growing importance of automated analysis of political discourse in low-resource languages, using the Kazakh language as a case study. As political communication in Kazakhstan has increasingly moved online between 2019 and 2023, the need for accurate tools to evaluate political sentiment has grown. However, limited linguistic resources in Kazakh have hindered tool development. This paper introduces the first annotated corpus of political discourse in Kazakh, comprising 3,022 sentences selected from official statements, televised debates, policy documents, and social media publications. Each text was manually annotated for political sentiment by expert linguists and political scientists, with inter-annotator agreement measured to confirm reliability. Two main methodological approaches were employed for automatic sentiment classification: adapting multilingual neural network models to the Kazakh corpus and testing advanced generative language models in scenarios with minimal training examples. Performance was evaluated using standard classification procedures. The inclusion of pragmatic features such as code-switching, rhetorical emphasis, and discursive context led to notable improvements in classification accuracy. Experimental results demonstrate that models adapted to multilingual input achieved high classification quality, with fine-tuned multilingual transformer models reaching F₁-scores of up to 0.90, while large language models reached an F₁-score of 0.94 in few-shot settings. Explicit modeling of code-switching and pragmatic features yielded an improvement of approximately 4 percentage points in F₁. This research contributes a practical resource and a methodological framework for analyzing political sentiment in underrepresented languages, highlighting the feasibility of developing high-quality automated tools for political text analysis without extensive training data.
Article Metrics
Abstract: 208 Viewers PDF: 130 ViewersKeywords
Full Text:
PDFRefbacks
- There are currently no refbacks.

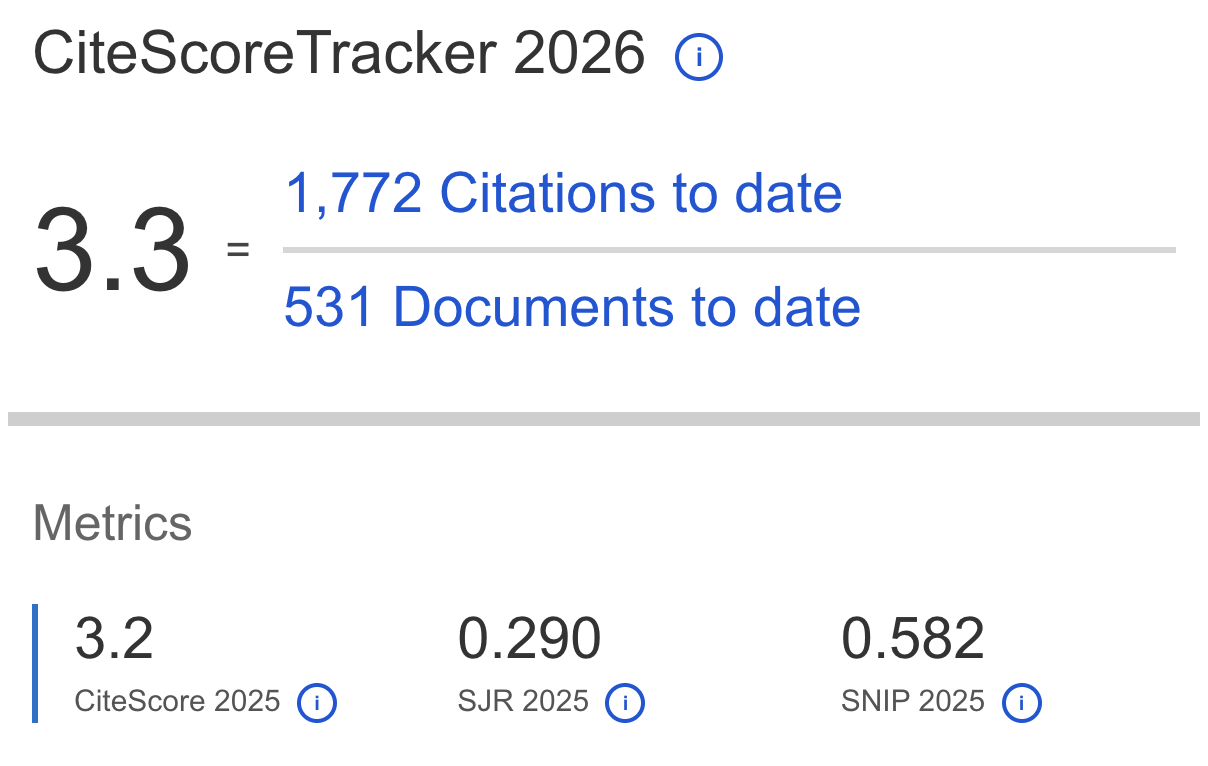
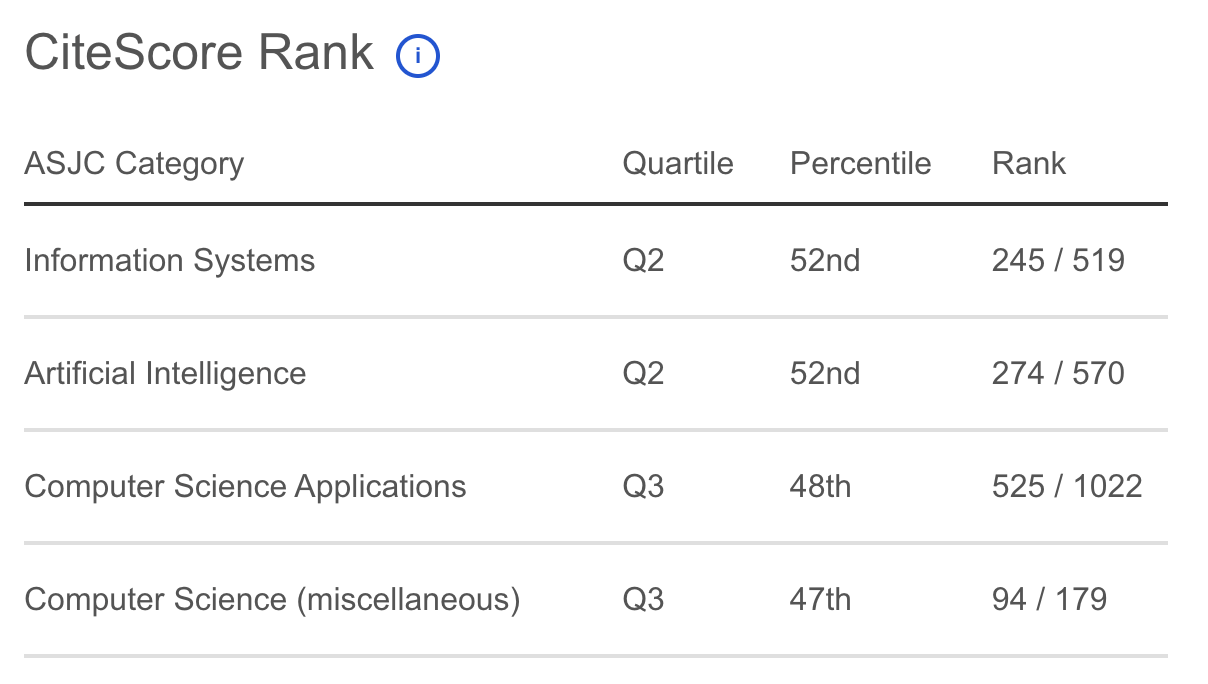
Journal of Applied Data Sciences
| ISSN | : | 2723-6471 (Online) |
| Publisher | : | Bright Publisher |
| Website | : | http://bright-journal.org/JADS |
| : | taqwa@amikompurwokerto.ac.id (principal contact) | |
| support@bright-journal.org (technical issues) |
 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0